近年来,NoSQL数据库发展迅猛,SQL越来越萎靡不振,似乎再无出头之日。事实上,随着大数据如日中天,结构化查询语言(也就是SQL)貌似已被淘汰出局。
然而枯木也有逢春时,2013年的大数据发展趋势中,最令人惊讶的方向便是SQL的老树发新芽。很多在大数据田野里耕耘的公司,重新认识SQL的价值,将其作为大数据分析的首要接口。
如今,基于Hadoop的大数据厂商,谁不提供SQL解决方案,谁就已然out了。“这简直令人难以置信。”权威专家评论说。
Hadoop是一个开源批处理数据存储与分析引擎,建立于Google的MapReduce架构与Google文件系统基础上。它是许多大数据分析工具的后台技术,用于筛选分析Web访问、服务器日志及其他各种数据流所产生的大量数据信息。例如,Facebook在Hadoop集群中拥有超过30PB数据,并创建了Hadoop前端工具Hive(属于Apache开源项目);而NSA用来进行情报数据实时分析的Accumulo数据库,也是基于Hadoop搭建的。
但掌握Hadoop殊非易事。用户要学习Hadoop,就要理解Hadoop的问题解决策略MapReduce,以及支持MapReduce任务的编程语言,以便使用MapReduce并行处理批任务来处理大量数据。然而SQL却是普及率极高的技术,可用于几乎所有关系型数据库,并且大量IT民工都能熟练地使用SQL来挖掘和分析数据。尽管Facebook所创建的Hive提供类SQL的Hadoop前端工具,但它不能兼容全部SQL语法,性能也不是特别快,因为它只是简单地把查询转换为Hadoop的MapReduce批处理作业。
因此,从2013年上半年开始,大数据厂商急用户之所急,提供既完全兼容SQL查询能力、又明显改进性能、且能运行于已有Hive/Hadoop系统上的数据分析工具。它们允许在数据仓库级别的数据集上使用完整的SQL查询,在大多数情况下还能彻底绕开Hadoop(部分采用混合方法)。因此,允许全面使用性能极大改进的SQL查询,就能使更多企业用户掌握大数据分析技术,并能适应现有工作流程。
下面是大数据SQL的部分在研项目:
- Facebook的Presto:实时查询引擎,提供直接SQL接口,面向Facebook的Hadoop数据仓库。Facebook已将其升级为开源项目。
- Amazon提供的RedShift服务:该服务提供基于SQL的数据仓库服务,可处理量达1.6PB的数据库查询。
- HortonWorks的Stinger项目:致力于改善Hive的SQL接口,使其性能提高100倍。
- IBM的BigSQL:Hadoop的SQL查询引擎,能够绕开MapReduce,使只读查询运行于Hadoop分布式文件系统之上、执行读写查询的交易查询运行于HBase (Hadoop数据库引擎)之上。
- EMC的HAWQ:SQL查询引擎,运行于EMC发布的Hadoop版本Pivotal HD之上。
- Cloudera的Impala:Hadoop的实时即席查询接口。
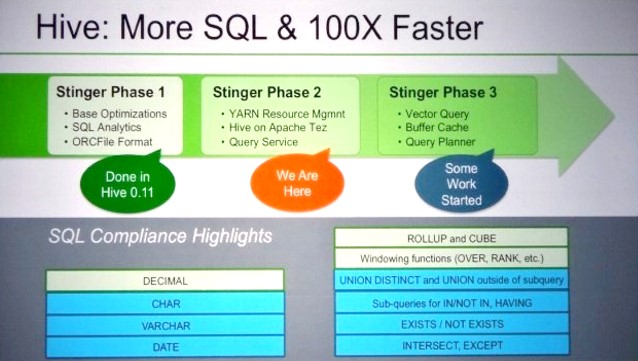
当然,另一个方向是改变Hadoop本身,使Hadoop的数据的SQL查询更加容易。Hadoop 2.0有望引入模块化架构YARN,以取代Hadoop中的MapReduce代码,使多种分析系统与MapReduce共存。因此YARN也被称为MapReduce 2.0。
本文根据The hot new technology in Big Data is decades old: SQL等英文资料编译。